系统架构组成:
如何实现T+0实时数据统计分析
传统数据集市T+1方式
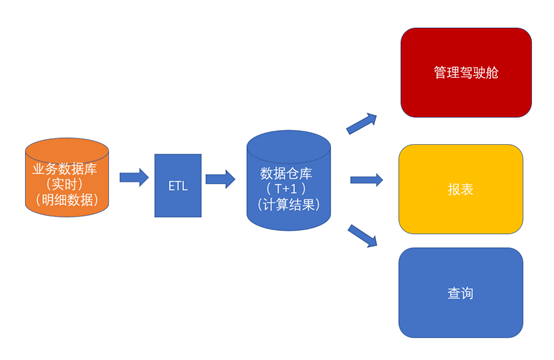
由于业务系统中的数据需要在分组聚合计算后,才能在报表或者管理驾驶舱中使用。所以常规的数据分析平台中,建立数据集市对业务系统的明细数据根据需要进行维度分组的聚合计算并将结果存储在数据集市中。后边会定期对数据集市的数据进行增量更新。对应的会有定时任务的周期,一般周期为晚上运行当天的数据到数据集市,当天只能查看到昨天的数据。
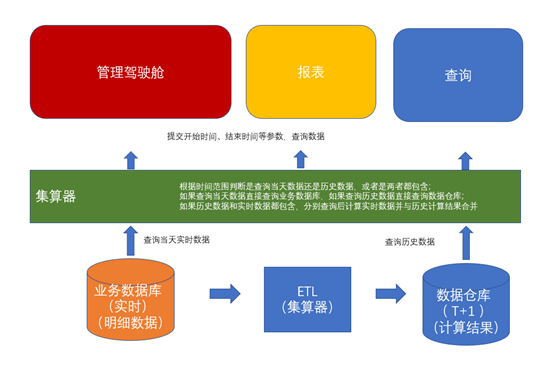
数据采集层:使用Kafka/Pulsar作为消息队列,接收来自各业务系统的实时数据流
数据处理层:
Flink/Spark Streaming进行流式数据处理
实时ETL和数据清洗
窗口计算和聚合操作
存储层:
ClickHouse/Druid用于实时OLAP分析
Redis存储中间计算结果和缓存
HDFS/对象存储用于原始数据归档
服务层:
微服务架构提供数据查询接口
实时监控和告警服务
展示层:Web前端配合Chart.js/ECharts实现可视化仪表盘
关键技术点:
采用Lambda架构或Kappa架构平衡实时与批处理
数据分区和索引优化查询性能
水平扩展保证系统弹性
数据一致性保证和容错机制
T+0实时数据统计分析系统架构解析
T+0实时数据统计分析指在数据产生后立即进行统计计算,实现秒级甚至毫秒级的数据可见性。以下是实现该目标的系统架构方案:
核心架构设计
数据采集层
实时数据源接入:通过CDC(Change Data Capture)技术、日志采集(如Kafka Connect)、API接口等方式实时捕获业务系统数据变化
数据传输:采用消息队列(如Kafka、Pulsar)作为数据管道,确保高吞吐、低延迟的数据传输
流处理层
实时计算引擎:使用Flink、Spark Streaming或Storm进行流式数据处理,支持复杂事件处理和窗口计算
数据预处理:在流中完成数据清洗、格式转换、业务规则处理等操作
存储层
实时存储:采用时序数据库(如InfluxDB、TDengine)或列式存储(ClickHouse)支持快速聚合查询
索引优化:建立合适的索引策略,如倒排索引、位图索引等加速查询
服务层
查询引擎:使用Druid、Presto等OLAP引擎提供即席查询能力
API网关:对外提供统一的数据服务接口,支持多协议访问
关键技术实现
流批一体架构
采用Lambda架构或Kappa架构,统一流处理和批处理的计算逻辑
使用Apache Iceberg、Hudi等数据湖技术保证数据一致性
实时OLAP方案
预聚合技术:通过物化视图、Cube预计算等方式提前聚合常用维度
向量化执行:利用SIMD指令提升计算性能,支持高并发查询
数据同步机制
基于Binlog的数据库变更捕获,保证数据不丢失
端到端延迟监控,确保数据实时性在可接受范围内
典型架构示例
text
Copy Code
数据源 → 消息队列 → 流处理引擎 → 实时存储 → 查询服务 → 前端展示
↓
批处理补充 → 数据湖 → 数据服务
这种架构能够支持:
实时监控看板:业务指标秒级更新
实时预警系统:基于规则引擎的即时告警
实时推荐:用户行为即时分析并反馈
实时反欺诈:交易数据的实时风险识别